温馨提示:本文共3824个字,读完预计10分钟。
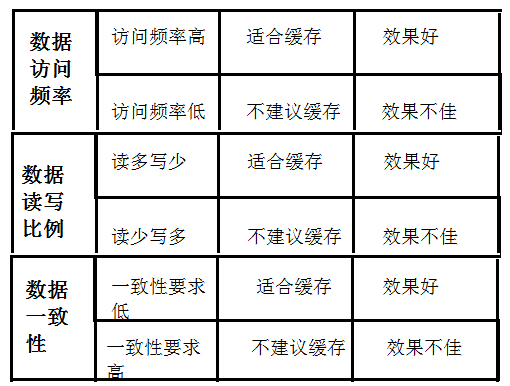
1、什么样的数据适合缓存?
2、What?
缓存穿透:
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
比如说,一个用户的基本信息(缓存key为uid)或订单的信息(缓存key为order_id),缓存或数据库里都没有这个uid或order_id的信息,但是如果有请求要获取这个信息,那么逻辑处理时就会跨过缓存这一层去查数据库,如果这样的请求短时间内非常多可能会压垮数据库。
缓存击穿:
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
比如说,订单的信息(缓存key为order_id)在缓存中有过期时间,如果在特定的时间这个订单信息在缓存中已经过期但是尚未从数据库查出最新的信息set到缓存上,恰好这个时候大并发请求过来了,那么这些请求的逻辑处理也会跨过缓存直接查询数据库,这个大并发的查询可能会压垮数据库。
缓存雪崩:
缓存雪崩是指在设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,导致所有的查询都落在数据库上,造成了缓存雪崩。
上面说到缓存击穿是一个key在特定时间过期,那么如果缓存系统中大量的缓存在同一时间或时间段内过期,这个时候的请求也会跨过缓存直达数据库,数据库压力陡增也可能会压垮数据库。
3、How ?
缓存穿透:
1)有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层数据库的查询压力。
2)另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),仍然把这个空结果进行缓存,附代码如下。
public function getCache($key) {
$redis = new Redis(); //redis对象
$expireTime= 120; //key过期时间依据实际情况而定
$result = $redis->get($key);
if ($result) {
return $result;
}else {
//新手入学版
//redis没查到,去查db
$dbData = querySelectDb($key); //模拟查询db,拿到db数据
if ($dbData) {
//正常情况下数据库查到的数据,更新缓存key数据,返回数据
$redis->set($key, $dbData, $expireTime);
return $dbData;
}else {
//数据库查不到该$key对应的数据,设置一个默认值,更新缓存key数据,返回数据
$dbData= 'Empty Data';
$redis->set($key, $dbData, $expireTime);
return $dbData;
}
//精简版
/**
* $dbData= $dbData?: 'Empty Data';
* $redis->set($key, $dbData, $expireTime);
* return $dbData;
*/
}
}
缓存击穿:
1)后台刷新
后台定义一个crontab job专门主动更新缓存数据.比如,一个缓存中的数据过期时间是30分钟,那么job每隔29分钟定时刷新数据(将从数据库中查到的数据更新到缓存中).
注:这种方案比较容易理解,但会增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务,key 比较分散的则不太适合,实现起来较为复杂。
2)检查更新
将缓存key的过期时间(绝对时间)一起保存到缓存中(可以拼接,可以添加新字段,可以采用单独的key保存..不管用什么方式,只要两者建立好关联关系就行).在每次执行get操作后,都将get出来的缓存过期时间与当前系统时间做一个对比,如果缓存过期时间-当前系统时间<=1分钟(自定义的一个值),则主动更新缓存.这样就能保证缓存中的数据始终是最新的(和方案一一样,让数据不过期.)
注:这种方案在特殊情况下也会有问题。假设缓存过期时间是12:00,而 11:59 到 12:00这 1 分钟时间里恰好没有 get 请求过来,又恰好请求都在 11:30 分的时 候高并发过来,那就悲剧了。这种情况比较极端,但并不是没有可能。因为“高 并发”也可能是阶段性在某个时间点爆发。
3)分级缓存
采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。 请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。
注:这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更 新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中 可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案 可能会造成额外的缓存空间浪费。
4)加锁
public function getCache($key) {
$redis = new Redis(); //redis对象
$expireTime= 300;
$result = $redis->get($key);
if ($result) {
return $result;
}else {
//redis里没查到,去查db
$mutexKey = $key . '_mutex';
//这里假设同时有10个查询的线程,1个线程抢到了这个锁,其他的9个线程就会阻塞或需要等待
if ($redis->setnx($mutexKey, 1, 60)) {
//抢到锁的线程,去执行数据查询,更新缓存这些操作
$dbData= querySelectDb($key);//模拟查询db,拿到的数据
$result = $dbData?: 'empty data';
$redis->set($key, $result, $expireTime);
$redis->del($mutexKey);
}else {
//没抢到锁的线程,就稍微等一会啦,然后再获取最新的缓存数据
sleep(0.1); //视情况而定
$result = getCache($key);
}
return $result;
}
}
缓存雪崩:
短时间大量数据读写操作极大可能导致数据库垮掉。为了避免出现这种情况,可以在常规的缓存set操作的基础上,在预设的过期时间基础上再额外增加一些时间;也可以单独起一个进程去监控redis中快过期的key,如果有快过期的key,就去重新查询更新。
1)在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2)可以通过缓存reload机制,预先去更新缓存,在即将发生大并发访问前手动触发加载缓存。
3)不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
4)做二级缓存,或者双缓存策略。A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
本文作者:杨宇飞
本文链接:https://www.cnblogs.com/afeige/p/13590450.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



